
The AI “Hallucinations” Project is an interdisciplinary initiative that transforms interpretations of algorithmic errors in the field of digital humanities inquiry and research. Fabrications or misrepresentations, otherwise known as “hallucinations,” produced by Large Language Models (LLMs) have been (mostly) treated as technical glitches. This initiative positions such errors as cultural artifacts. The project is a systematic documentation of errors made by popular LLMs –– ChatGPT, Gemini and Claude — in response to prompts about Black American and Puerto Rican histories of the 19th and 20th centuries. by building on the Black Knowledge Erasure Dataset (BKED) dataset.The AI Hallucinations Project is a dataset of 150+ “hallucinations,” their prompts, the models that produced them, and the accessible archival resource that provided the accurate response. It is a record of AI hallucinations not as bugs, but as cultural artifacts that reveal how algorithms distort or erase the histories of marginalized communities. It argues that every question about marginalized histories is an opportunity to learn from the archives. It provides a platform that is fundamental for critically analyzing how algorithmic errors and bias occur within the complex (algorithmic) systems of and behind AI-generated content.
Recent, rapid integrations of AI technologies across various industries and environments, especially education, have facilitated the need for (and encourages) intense examinations of model reliability. University of Maryland Researchers note the evolution of digital capabilities in telecommunicating misinformation as well as numerous real-life examples of resulting consequences, which is permeated by AI technologies. The researchers, driven by their interests in the implications of AI-generated falsities, find that any form of artificially generated content (text-based, audiovisual material) is designed to appear legitimately credible regardless of truth or accuracy. Such features are helpful to user experience when LLMs are carefully prompted to uncover and repair informational mistakes. They recognize that the abilities of generative AI to produce and mitigate misinformation mostly, as a tool, exacerbates or influences user behaviors (Park et al. 2025). Researchers at University Canada West have a generally supportive framework, arguing that Artificial Intelligence improves research efficiency within academia, thus highlighting its capabilities to sustain research competency in additional industries. They recognize, however, legal standards that are controversial due to ownership and creation, as well as the perpetuation of biases and inequities connected to historical oppressions and socioeconomic disadvantages (Madanchian et al, 2025). Lastly, scholars and research figures from the Stanford Institute for Human-Centered Artificial Intelligence examined the various effects of AI technologies on African American communities. It has proven useful in general education, medical care, as well as employment, while prone to algorithmic bias since bias is embedded within the data sources of many mainstream AI models (Djanegara et al. 2024). The diverse range of perspectives mentioned here represent extremely few academic voices, though connected to broader observations and critical studies of Artificial Intelligence’s implementation across academia and various industries where research is imperative. Historical inquiry is not exempt, which is where the AI “Hallucinations” Project enters as a tool for observing informational errors and most crucially, specific examples of how errors were generated.
Dartmouth professor Roopika Risam published New Digital Worlds: Postcolonial Digital Humanities in Theory, Praxis, and Pedagogy in 2019. Even though its publication is before recent ubiquitous expansions of public Artificially Intelligent models and services, her rhetoric describes the approaches undertaken in the development of the AI “Hallucinations” Project. She defines postcolonial digital humanities “an approach to uncovering and intervening in the disruptions within the digital cultural record produced by colonialism and neocolonialism.” Furthermore, remarks that DH praxis creates unique methodologies for literary, historical, and socio-cultural analysis, demonstrating a continuation of historical practices in humanities knowledge production promoted by interdisciplinary approaches, involving perspectives and practices from an array of academic backgrounds. These interventions in particular, open different routes for investigating questions of the authority held by mostly Western and US-based technology corporations, positioning respective practitioners to study the influences of associated ideologies on various digital cultural environments, notably the internet (Risam, 2019, pp. 3-4, 9-10). Risam’s explanations for postcolonial methods in Digital Humanities embodies a framework that is consistent with digital colonialism, which Toussaint Nothias defines as a kind of critique aimed towards technological corporations – mostly of Western origin. Moreover, digital colonialism rhetorics assert that prominent tech corporations operate in manners that prioritize chances of attaining revenue, even if it harms the interests and security of a user who could be vulnerable, marginalized, or otherwise arriving from an underprivileged background (Nothias, 2025). The AI “Hallucinations” Project, with our backgrounds, discussions, approaches, and goals considered, represents a postcolonial intervention as it outlined by Risam, supported by Toussaint Nothias.
Introducing Roopika Risam is appropriate for understanding the decisions and processes undertaken to build the AI “Hallucinations” Project. Postcolonial digital humanities, according to the professor, involves a diversity of scholarly and practical backgrounds who are interested in critical examinations of the Generative-AI technologies put out to the public. Scholars involved in the further development of the project, after initial completion of the Black Knowledge Erasure Dataset, have experiences that range from documentation, public outreach, historical research, interface design, website development, and coding. Furthermore, we demonstrate commitment to the tradition of humanities knowledge production by merging these skillsets in a manner that enabled everyone to contribute efficiently to development, especially by remembering findings from research referenced above. It is also worth recognizing projects that partially inspired this initiative. More specifically, the AI Incident Database providing real-world cases of harms and mishaps involved AI technologies; additionally, TruthfulQA functioning as a benchmark for studying the degree of truth generated by artificially intelligent language models. The AI “Hallucinations”Project,” expands layers of perspectives about AI and presents a specific method for learning how information on real (past) experiences are generated as a result of generative models recollecting; in other words, analysis of algorithmic output. Furthermore, The Project encourages interventions in potential instances of epistemological manipulations, promotes pedagogies for studying AI distortions, and gives evidence of misattributions, factual errors, invented figures and other subjects, and other types of error generated by a Large Language Model, when inquired about experiences of historically marginalized communities. Considering that our project is concentrated within the humanities, the OER produced is not intended solely for academic analysis of AI legitimacy in retelling the past. Rather, potential studies referencing the published database can apply to environments where AI technologies serve members of the general public.
Audiences
According to a recent survey by the Pew Research Center, more than half of US teens use AI chatbots for “information-seeking schoolwork,” while comparable studies on college students yield higher percentages. This is the age group that makes up the majority userbase of products like ChatGPT, Google’s Gemini, and Claude. The gains earned by Black and Puerto Rican activists seeking to have their communities histories properly acknowledged by the education system and taught in American classrooms stands to be undermined when these students turn to LLMs that rely on low-quality data, biased algorithms and misaligned value systems to do their history or literature homework. The AI Hallucinations Project, first and foremost, documents the extent to which these profit-seeking services are depriving today’s students from learning and engaging with these important histories. The students who are turning to these models to speedrun assignments are wanting in digital resources that address their needs and speak to their realities. Our project offers a self-guided intervention: Students can focus on close-reading the hallucinations and learning about accessible alternatives, or they can scroll through the Are.na board where memes and journal articles co-exist as complementary rhetorical tools. What our project does and LLMs fail to supply, is a sense of real agency that encourages personal judgment and discernment.
Educators, our second audience, can turn to the AI Hallucinations Project as a tool for their own development, or an ongoing reference they can resurface in the classroom. While the AI Hallucinations Project is best navigated individually in an open-ended session where agency and curiosity lead the way, there is room for teachers and other educators to play a supporting role through class discussions or worksheets. We remain actively interested in connecting with educators who are curious about using our website, our Are.na board or our datasets.
But the Pew Survey’s findings regarding high school students’ use of AI chatbots for “information-seeking schoolwork” was conducted before Google announced its most significant search update in 25 years: A search box redesign that will integrate AI chatbots and turn all search queries into model queries. Which makes the topic of this project all the more relevant to the general population, or, at least, anyone who even casually uses Google’s search engine. Across all audiences, a successful interaction with the project would lead a visitor to internalize the questions the project raises.
Project Activities
Research and Fact-Checking
This project’s first order of business was to begin work on developing a new dataset dedicated to hallucinations about Puerto Rican and Diasporican histories of the 19th and 20th centuries. The Research Lead found that accessible online resources such as EnciclopediaPR and Puerto Rico in the American Century: A History Since 1898 (2009) were found to begin ensuring research organization, by setting up team members to seek out prompt ideas from known locations if needed. Next, Christian shared the links of up to 10 digital archives containing evidence of Puerto Rican experiences originating in the 19th and 20th centuries. Although it was ultimately decided that three main archives (the Center for Puerto Rican Studies, Library of Congress, Rutgers University Puerto Rican Archival Collaboration) would get explored during project development common set of standards were still needed for prompt engineering and identifying types of hallucinations generated. The first result is a set of guidelines that would standardize prompt writing by focusing on questions that begin with 5 Ws and 1 letter H (Who, What, When, Where, Why, and How),and discouraging prompts that would be considered unnecessarily complicated and would probably originate from an essay question on an Advanced Placement history exam. Once the prompts were executed, Christian examined data from the BKED to develop hallucination type categories and standardized definitions. The first round of fact-checking and categorization was split among the three team members before a final round of fact-checking and categorization was carried out by the Research Lead.
Technical Development
The technical development of the AI Hallucinations Project focused on creating a robust pipeline for data collection, validation, and public dissemination. To achieve a functional Minimum Viable Product (MVP), the team’s developer implemented a tech stack centered on Python, GitHub, and standard web technologies. The core data architecture relied on Python scripts designed to automate structured query prompts sent to the APIs of major Large Language Models (LLMs), specifically GPT-5, Google Gemini, and Claude. These scripts (e.g., collect_records.py and append_records.py) captured raw model outputs as JSON files, which were then aggregated and transformed into structured CSV datasets for human annotation.
To maintain data integrity across the project’s two parallel datasets, the Black Knowledge Erasure Dataset (BKED) and the Puerto Rican history dataset, the team utilized JSON and CSV schemas for strict validation of metadata fields such as “error_type” and “verification_source”. GitHub served as the central repository for version control, issue tracking, and collaborative development, ensuring that the code architecture remained transparent and reproducible.
The project’s front-end was developed as a public-facing web archive using HTML, CSS, and JavaScript. The technical architecture was designed as a static site to host the explorable database, featuring interactive elements that allow users to filter over 140 records of verified hallucinations by demographic category and error type. Data visualizations, including comparative charts showing hallucination rates across different model families, were integrated using Chart.js to transform static data into accessible, empirical evidence. This streamlined infrastructure ensured high performance and reliability while meeting universal design standards without the overhead of complex back-end server maintenance.
While our initial proposal included stretch goals, such as implementing dynamic front-end frameworks like React or Vue, or integrating a dedicated back-end database, we scaled these back to ensure we met our project deadline. We determined that a static, minimally interactive site hosting structured CSV data was more feasible and perfectly aligned with our primary goal of making the data accessible. During the final deployment phase, we also adjusted our infrastructure by executing a domain transfer to Reclaim Hosting; our website is hosted on Reclaim Hosting courtesy of the GC Library and GC Digital Initiatives.
The technical milestones outlined in our initial Work Plan accurately reflected the project’s overall trajectory. However, the post-spring break phase proved to be the most logistically demanding, as technical development was strictly gated by the dataset verification workflow. We could not build the comparative hallucination rate charts or integrate the explorable database until the curation tasks were fully completed. Navigating this bottleneck underscored the critical importance of our collaborative team structure; continuous team communication and shared accountability ensured that our technical implementation seamlessly supported the rigorous research objectives, ultimately allowing us to test and deploy the live explorable database on schedule
Web Design and Community Building
The website’s overall design and layout were executed as planned. We chose to list the hallucinations on the main page, with a drop-down feature for each that included the prompt, model, and fact-checking details for each. Separate pages — all listed at the top of the website — each housed downloadable datasets and links to their corresponding GitHub repositories, methodology details, an About section, and links out to an Are.na board where books recommendations, journal articles, memes, articles, archives and other resources for additional resources were listed.
Minor chances in design and web layout arose when we realized text-based pop-ups added visual clutter rather than easier points of entry. So the decision was made to populate the pop-ups with data visualizations based on the insights gleaned from the dataset, and to add introductory text to the main page to infuse it with narrative and ease in the visitor. This had a rippling effect in the rest of our public-facing materials: While the original plan included a series of 500-800 word “mini essays” that engaged in easy-to-read criticism about subjects ranging from the anthropomorphising effect of the term “hallucination,” generative AI’s parasitic relationship to knowledge production ecosystems, and the methodologies used to develop the datasets.These mini-essays would also double as content for future newsletters, but since the immediate needs shifted, we pivoted instead towards writing one long blog post-style text to send in a welcome email. Three total versions of our core statement were drafted: a “micro” version (40 words) to use when a two-sentence description is required, a 100-word version for the top of the homepage that can double as mid-length project descriptions to share for future appearances, introductory emails, or similar cases, and a long 500-word version (the blog post text in the welcome email). As a result, the mini-essays were not produced and the future email sends will be written on an as-needed basis.
Our original outreach strategy shifted away from distributing the website’s links across link repositories across the internet, and leaned, instead, on relying on word-of-mouth. We knew that for a project that primarily lived on a standalone website would rely on a relatively dormant, but hopefully long afterlife of visitors and engagement. We do not think this is an undesirable outcome, in fact, this is what successful outreach and dissemination look like. Our idea of success, as far as outreach is concerned, has not changed: Successful dissemination is when the link to the website earns its place among people’s personal collections of internet artefacts or among institutions’s list of recommended resources. The Are.na board is well-situated to reach its intended audience of designers, scholars, amateurs, hobbyists, autodidacts, and arts and culture workers.
However, we were hoping to identify 10-15 link repositories — user-generated spreadsheets, links compilations, etc. — where the website link might find interested audiences, and ended up with just under five. Additionally, technical difficulties during the domain transfer phase delayed our web development timeline and we were not able to have a shareable link until presentation day. As a result, we focused on developing our mailing list and newsletter workflow (more on that below), to ensure the project is shareable on a continuous basis.
Accomplishments
The culmination of our development phase is the successful deployment of the AI “Hallucinations” Project website, which directly achieves our proposed objectives by functioning simultaneously as a comprehensive digital archive and a critical analysis tool. This public-facing, explorable website systematically catalogues how prominent large language models fabricate, distort, or entirely erase the histories of marginalized communities. By fulfilling our quantitative and qualitative goals, we have produced a robust Open Educational Resource (OER) that equips students, educators, and scholars with the concrete empirical evidence required to actively challenge perceived algorithmic authority and neutrality.
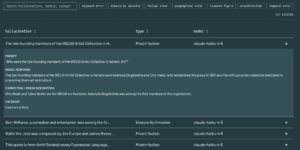
The central affordance of the prototype is its highly interactive, explorable database. This interface empowers users to granularly filter AI “lies” by specific demographic categories, focusing explicitly on the 19th and 20th-century histories of Black Americans and Puerto Ricans. The search architecture allows visitors to isolate specific modes of algorithmic failure through a rigorous, controlled vocabulary of error types, which includes “Adjacent Error,” “Erasure By Omission,” “Factual Error,” “Geographical Error,” “Invented Figure,” “Misattribution,” and “Temporal Error”. Each entry within this database exposes the mechanics of epistemic erasure by displaying the original prompt, the unedited output generated by major model families (GPT-5, Gemini, and Claude), and a detailed, human-verified correction. Crucially, every curator-led correction is grounded in and verified against gold-standard historical repositories, such as the Schomburg Center for Research in Black Culture and the Center for Puerto Rican Studies.
Beyond the searchable database, the website features an array of dynamic data visualizations designed to synthesize and communicate our key findings. These include a primary visualization chart and comparative hallucination rate charts that illuminate how epistemic erasure and cultural distortions function differently across specific diasporas and distinct language models.
The site is structured with dedicated “About,” “Methods,” and “The Data” sections. These pages host short, critical essays that interrogate the anthropomorphizing effect of the term “hallucination,” examine generative AI’s parasitic relationship to established knowledge production ecosystems, and transparently document the methodologies utilized to develop the datasets. By reframing these technological glitches as significant cultural artifacts , the platform affords critical AI researchers, investigative journalists, and archivists the structured data necessary to conduct targeted audits of model behavior and report on the quantifiable harms of algorithmic bias. Furthermore, to ensure ongoing interoperability and reuse, the website provides direct access to our GitHub repository, allowing users to freely query and download the raw datasets for further interdisciplinary research.
In addition to the primary website, a supplementary digital product developed is the project’s dedicated Are.na board. The board has evolved into a central component of our organic outreach and dissemination strategy. The board serves as a publicly accessible repository of our intellectual framework. We curated foundational literature and annotations on algorithmic bias and AI ethics, including extensive excerpts from texts like Algorithms of Oppression and “On the Dangers of Stochastic Parrots”. This platform was strategically chosen over traditional, algorithmically-driven social media to deliberately embed the project within digital communities of researchers, designers, and technologists. By positioning our research materials here, we ensured the project’s resources could be seamlessly integrated into user-curated link repositories, digital toolkits, and academic bookmarks, effectively sustaining the project’s afterlife and extending its educational impact to highly engaged, “very online” users.
Evaluation
Responses and Feedback
During the project’s dressed rehearsals, a consultation meeting with the Graduate Center Digital Initiatives (GCDI) fellows, and a one-on-one with Luke Waltzer (Director, Teaching and Learning Center), we received invaluable feedback that prompted a reassessment of both our technical outputs and conceptual framing.
Feedback on our prototype website and presentation highlighted the need for immediate clarity. Evaluators noted that the website’s visual design featured a scrolling background that was too “busy” and distracted from the data; we planned to remove this to ensure the misrepresentations were clear at first glance. Evaluators also suggested that our methodology section read too much like a technical manual and advised us to craft it into a “narrative” that tells a story.
In preparation for our public showcase presentation, feedback urged us to spend less time on the granular methodology and instead boldly state the project’s overall importance and goals on the initial slides. To improve audience engagement, we were advised to replace heavy text with a moving GIF demo of the website, describe the “less obvious” hallucination categories in greater detail, and conclude with clear takeaways, future directions, and an open invitation for collaboration.
Conceptually, our GCDI meetings challenged us to refine how we frame and categorize “hallucinations.” Evaluators asked a profound guiding question: How does AI that follows compliance continue to perpetuate harm?. This led to a reassessment and realignment of our error categories to better focus on the specific types of harms we wanted to analyze. We explored the “degrees of rightness/wrongness,” questioning if we could measure how confident the language of the AI’s response was, often referred to as “temperature error”. Furthermore, feedback on our prompt-writing process reminded us that historical truth is often subjective; we had to be highly conscious of the “assumptions within the questions,” noting that affect-loaded narrative questions can inherently spark debate.
Project Strengths & Weaknesses
The primary strength of the project lies in its rigorous, human-in-the-loop fact-checking methodology and its conceptual reframing. By treating AI hallucinations not merely as technical glitches but as “cultural artifacts,” the project successfully established a framework for evaluating algorithmic errors. We met our Minimum Viable Product (MVP) deadline by strictly adhering to our Project Work Plan and consciously scaling back our technical ambitions. Relying on a streamlined static tech stack rather than complex dynamic frameworks allowed us to focus our resources on data integrity and empirical validation against gold-standard archives.
Despite its successes, the project faced several logistical and technical limitations. One significant weakness was the bottleneck created during the post-spring break period, which became logistically demanding as dataset cleaning, annotation, and web development workstreams converged simultaneously.To address this, we made the decision to scale back on the Puerto Rican history dataset.
Technically, our decision to scale back the website meant we could not implement advanced database-driven search and dynamic filtering mechanisms that a dedicated back-end server would provide. However, as a functional compromise, we successfully implemented a localized search bar and filtering functionality on the front-end, allowing users to seamlessly sort the 147 records by error type and model directly on the site.
What Could Have Been Done Differently?
If the project were to be repeated or expanded, rather than simply incorporating new tests, we could have conducted a comparative analysis of our methodology versus “Red Teaming” strategies. Red Teaming is a hands-on exercise where participants intentionally test Generative AI models for flaws and vulnerabilities that may uncover harmful behavior. Historically, this practice has traditionally been carried out by major tech companies and specialized AI labs behind closed doors. By comparing this industry-standard practice against our own human-in-the-loop, archival verification approach, we could critically ask: “Are there things we are doing that they didn’t?”.
We would also explore integrating an “Agentic AI Process” (such as using Claude desktop) to automate parts of the verification workflows. Finally, as a key area for future research, we would prioritize exposing the sparse training datasets behind the models. This would provide deeper context into why culturally specific “adjacent errors” and misattributions occur, ultimately helping us fulfill our main goal of providing a more robust and actionable critique of AI systems.
The Future of the Project: Continuation + Sustainability
One of the goals of the AI Hallucinations Project was to build a website that could live on as an argument, a work of criticism that doubles as a teaching tool. The language and narratives on the website position the work as an artefact of its time, anticipating the speed of change in AI product development (and the criticism that follows). Our work’s value comes from its rhetorical potential – it’s a collection of case studies that can be discussed in the classroom, or iterated on by whomever finds the dataset on Github or Are.na. Expanding and refining the core dataset in the future will certainly enhance this value, but the project does not stand to lose anything if these potentialities are not pursued. A rhetorical tool is only as good as the communities that use it and the discursive possibilities it engenders. The near future of the AI Hallucinations Project will be dedicated to reaching new audiences and capturing their attention in a sustainable way.
We optimized for longevity and ease of continuity by developing a modular design system and applying the same principles to other components, like copy. The first step taken in the name of maintaining and sustaining the project was to compile a “toolkit” of design assets, shareable links, and copy that can be applied to a range of needs and contexts, or passed onto other designers who will be saved the effort of having to guess or re-create design decisions made years prior. Fonts, color codes, logos (in a range of colors and sizes) QR codes (in various colors), were compiled in shareable formats on a shared Google Drive as soon as those decisions were made. Various versions of promotional language and website copy — of different lengths, for different audiences — were also compiled. External and shareable links to the website, GitHub and Are.na page were also compiled in the same “Post-Mortem” document, along with important internal details such as account credentials, API keys and more. If ever the need arose to create a new web page, design a new deck for a presentation, provide a brief description to be bundled along with conference materials, a new social media profile, or continue the work done in this phase in a new iteration of the project — anyone with access to the “Post-Mortem” document will be able to do so in a way that is consistent with the project’s existing branding, visual language and ethos.
The second step taken for the sake of easy maintenance involved spending down our budget. Our budget was exclusively dedicated to paying for services and subscription terms that would make the maintenance of our website and consistent engagement with our community as seamless as possible through — at least — May 2027. The terms of these services provided an intuitive length for the first phase of project continuation and served as its primary structure. The subscription lengths of our domain name (3 years), Linktree, mailing list, and hosting services (1 year, each) set the terms for how (and for how long) we would have to maintain the website, and we found that small upgrades proved majorly instrumental. We are using Linktree (as a simple way of packaging and sharing the project’s main offerings – the website, the dataset, the Are.na board. The Pro plan ($144/year) includes a Mailchimp integration that allows visitors to sign up for our mailing list directly in the Linktree. On the back-end, this plan allowed us to customize our QR code using our chosen colors and incorporating our logo, which prompted us to pre-design several iterations and added to our shared toolkit.
Through Mailchimp’s Essential plan ($130.65/year), we were able to set up an automated welcome email for anyone who joins the mailing list. Visitors to our website are prompted to subscribe to the mailing list via pop-ups, and anyone who clicks into the Linktree will be asked to do the same. Upon sign up, subscribers will receive an automated welcome email that summarizes the core tenants of the AI Hallucinations Project, lists each of the offerings (database on homepage, GitHub repository, Are.na reading list, visualized findings) and includes links. This will ensure the website is “saved” in people’s inboxes, and is easy to return and reference.
The primary challenge of sustainability will be a financial one: Once the year-long subscriptions plans to Linktree and Mailchimp lapse, we will have no way of capturing emails or sustaining the attention of those who find a link to the AI Hallucinations Project website via our Are.na board, an old QR code, or rediscover it in the welcome email they got in their inboxes. By May 2027, we will also have to decide if we want to pay for another year of web hosting via Reclaim or find an alternative. There are no immediate plans for where the project will be by then, and it’s possible that web hosting changes might not pose an existential threat to the project if it has evolved into a different kind or website or tool. And even if this is the end of the AI Hallucinations Project, the website has been archived on the Wayback Machine, and the link to that is on the Are.na board, where more people can find it.
Bibliography
Caroline Meinhardt, Daniel Zhang, Ezinne Nwankwo, Haifa Badi Uz Zaman, Gelyn Watkins, Michele Elam, Nina Dewi Toft Djanegara, Russell Wald, Rohini Kosoglu, Sanmi Koyejo, “Exploring the Impact of AI on Black Americans: Consideration for the Congressional Black Caucus’s Policy Initiatives,” The Stanford Institute for Human-Centered Artificial Intelligence (2024) https://hai.stanford.edu/assets/files/2024-02/Exploring-Impact-AI-Black-Americans.pdf
Mitra Madanchian, Hamed Taherdoost, “The impact of artificial intelligence on research efficiency,” Results in Engineering, Volume 26 (2025)
https://www.sciencedirect.com/science/article/pii/S2590123025008205#sec0022
S. Park and X. Nan., “Generative AI and misinformation: a scoping review of the role of generative AI in the generation, detection, mitigation, and impact of misinformation,” AI & Soc (2025). https://link.springer.com/article/10.1007/s00146-025-02620-3#citeas.